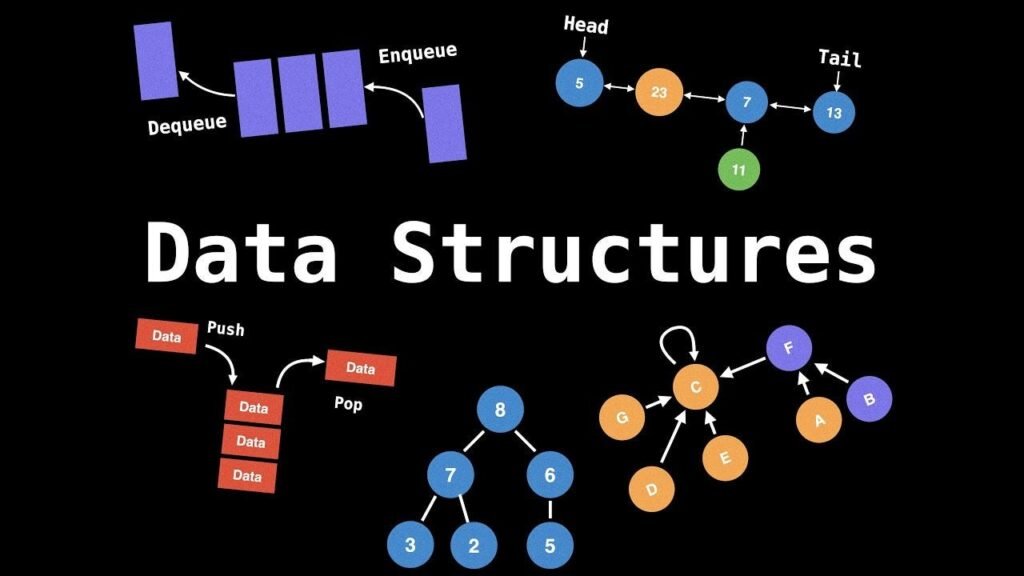
In the realm of computer science, data structures play a crucial role in organizing, managing, and storing data efficiently. Without effective data structures, even the most powerful algorithms would struggle to perform optimally. Understanding the various types of data structures and their applications is essential for anyone looking to develop robust, efficient, and scalable software.
In this blog, we will explore what data structures are, why they matter, and take a look at some of the most common data structures used in computer programming today.
What is a Data Structure?
A data structure is a specialized way of organizing and storing data in a computer so that it can be accessed and modified efficiently. Depending on the type of data and the operations required, different data structures are employed to optimize the performance of algorithms.
Data structures define how data is stored, how relationships between data are managed, and how data is processed. They also provide methods for adding, deleting, updating, and accessing data.
Why Are Data Structures Important?
Efficient data structures are essential for writing optimized algorithms. Poorly organized data can lead to slow program execution and poor performance, especially when dealing with large datasets.
Key reasons why data structures matter:
- Optimized Performance: Well-chosen data structures reduce time complexity and improve the efficiency of algorithms.
- Memory Management: Proper data structures allow for efficient use of memory, ensuring programs don’t consume more resources than necessary.
- Data Organization: They allow for clear and logical data organization, which simplifies code development and maintenance.
- Reusability: Certain data structures can be reused across different programs, saving time in development.
Types of Data Structures
Data structures can be broadly classified into two types:
- Linear Data Structures
- Non-linear Data Structures
1. Linear Data Structures
In linear data structures, data elements are arranged sequentially, and each element is connected to its previous and next element. Some common linear data structures include:
- Array: A collection of elements, each identified by an index or key. Arrays are simple, but their size is fixed, which can be limiting.
- Linked List: A collection of nodes where each node contains data and a reference to the next node. Linked lists are dynamic, allowing for easy insertion and deletion of elements.
- Stack: A data structure that follows the Last In, First Out (LIFO) principle. Data is added and removed from only one end, called the top of the stack. Stacks are often used in function calls and backtracking algorithms.
- Queue: A data structure that follows the First In, First Out (FIFO) principle. Data is added from one end (the rear) and removed from the other (the front). Queues are useful in scheduling tasks, buffering, and handling asynchronous data.
2. Non-Linear Data Structures
In non-linear data structures, data elements are not arranged sequentially but are connected through relationships like parent-child or hierarchical structures. Some common non-linear data structures include:
- Tree: A hierarchical structure consisting of nodes. Each node contains data and references to its children. The topmost node is called the root, and the nodes with no children are called leaves. Trees are useful in representing hierarchical data such as file systems or organizational charts.
- Binary Tree: A special kind of tree where each node has at most two children. Binary trees are commonly used in searching algorithms like binary search.
- Graph: A collection of nodes (also called vertices) and edges that connect pairs of nodes. Graphs can be directed or undirected and are widely used in networking, social media, and optimization algorithms.
Common Data Structures and Their Uses
- Array
- Uses: Storing multiple items of the same type, like a list of numbers or strings.
- Advantages: Simple and efficient for small datasets with a fixed size.
- Disadvantages: Fixed size and difficult insertion and deletion.
- Linked List
- Uses: Dynamic memory allocation, where frequent insertion and deletion occur.
- Advantages: Efficient for dynamic memory and inserting/removing elements.
- Disadvantages: Requires more memory due to pointers and slower access times.
- Stack
- Uses: Undo operations in applications, recursive function calls, expression evaluation.
- Advantages: Simple, supports LIFO operations, and is memory efficient.
- Disadvantages: Limited to LIFO operations, which may not suit all applications.
- Queue
- Uses: Job scheduling, handling requests in systems like printers, CPU task scheduling.
- Advantages: Supports FIFO operations and is useful in scenarios where order of operations matters.
- Disadvantages: Limited to FIFO operations, and like stacks, unsuitable for random access.
- Tree
- Uses: Hierarchical data storage (e.g., organizational structures, file systems).
- Advantages: Fast searching, insertion, and deletion operations compared to arrays and linked lists.
- Disadvantages: Complex implementation and higher memory usage.
- Graph
- Uses: Modeling networks, social graphs, and solving problems like shortest path, network flow.
- Advantages: Highly flexible and useful for complex relationships.
- Disadvantages: Complexity in traversal and algorithm implementation.
Advanced Data Structures
Beyond basic data structures, there are advanced data structures that offer more sophisticated functionality:
- Hash Table: A data structure that maps keys to values. Hash tables are widely used for fast data retrieval, such as in dictionaries or databases.
- Heap: A specialized tree-based data structure that satisfies the heap property, which makes it useful in priority queues and heap sort algorithms.
- Trie: A tree-like data structure used to store dynamic sets or associative arrays. Tries are most commonly used for word searches and auto-complete functions.
Conclusion
Data structures form the backbone of efficient algorithms and systems. By selecting the right data structure for a specific task, developers can dramatically improve the performance, scalability, and maintainability of their applications. Whether you’re handling large volumes of data or implementing complex algorithms, understanding and mastering data structures is key to becoming a proficient programmer.
At Techstertech.com, we specialize in designing systems that leverage the most efficient data structures to ensure optimal performance. If you’re looking to build fast, scalable, and robust software solutions, feel free to reach out to us for professional guidance.
For more information and expert web development services, visit Techstertech.com.